par Philippe Godet
Partager
par Philippe Godet
Partager

Pour une IA équitable
Les algorithmes n’ont pas d’opinion propre. Pourtant, ils peuvent discriminer, exclure, ou favoriser certains groupes au détriment d’autres. Pourquoi ? Parce qu’ils héritent des biais qui se nichent dans nos données et nos décisions passées. Lorsque les systèmes d’intelligence artificielle (IA) sont nourris d’historiques marqués par les inégalités sociales, ils reproduisent – et parfois amplifient – ces déséquilibres. C’est ce qu’on appelle le biais algorithmique.
Cet article niveau avancé est accessible à tous. Il a pour objectif de vous faire comprendre comment fonctionne une IA pour mieux vous préserver de ses erreurs. Il vous servira par ailleurs à configurer votre propre IA si vous souhaitez l’utiliser pour des analyses ou des tâches complexes.
Les conséquences des biais algorithmiques sont majeures : discrimination dans l’octroi de prêts bancaires, inégalités à l’embauche, erreurs dans l’évaluation des risques judiciaires.
Comprendre l’origine de ces biais, apprendre à les mesurer et mettre en place des stratégies pour les corriger est essentiel. C’est la première étape pour construire une IA plus responsable, plus éthique et, surtout, plus équitable.
1. Pourquoi des biais apparaissent ils ?
Les biais algorithmiques ne viennent pas d’une intention malveillante des ingénieurs ou des chercheurs, mais des données imparfaites et du contexte social dans lequel elles sont produites. Voici trois sources majeures de biais :
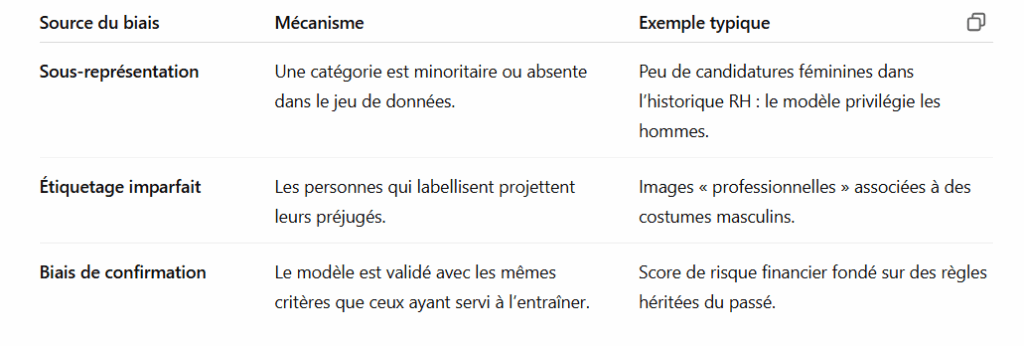
Causes des biais algorithmiques
L’algorithme ne devine pas la réalité : il apprend de ce qu’on lui donne. Si on lui donne des exemples biaisés, il va les généraliser.
2. Mesurer l’équité
Avant de corriger un biais, il faut savoir le mesurer. Plusieurs métriques simples permettent de réaliser un premier diagnostic :
-
Demographic Parity (parité démographique) : Le taux d’acceptation ou de prédiction positive est-il similaire pour tous les groupes ?
Exemple : 80 % d’acceptation pour les hommes, 50 % pour les femmes → déséquilibre clair. -
Equalized Odds (parité des chances) : La précision (taux de bonnes réponses) et le rappel (capacité à identifier tous les cas positifs) sont-ils équivalents selon le genre, l’âge, l’origine, etc. ?
Exemple : un modèle médical plus précis pour les hommes que pour les femmes. -
Statistical Parity Gap (écart de parité statistique) : Quelle est la différence absolue entre les groupes ? Un écart supérieur à 5 % est souvent jugé préoccupant.
Exemple : 70 % de prêts accordés à un groupe contre 60 % à un autre → écart de 10 %.
Ces mesures ne disent pas tout, mais elles offrent un premier aperçu utile pour identifier où se situent les problèmes.
3. Stratégies d’atténuation
Une fois les biais repérés, plusieurs stratégies existent pour les atténuer, à différents moments du cycle de vie du modèle.
-
Pré-traitement
-
Sur-échantillonnage des classes minoritaires.
-
Génération de données synthétiques (par exemple, créer des CV féminins pour enrichir un jeu RH).
-
Neutralisation des attributs sensibles (comme le genre ou l’origine).
-
-
In-processing
-
Ajout d’un terme de régularisation équitable dans la fonction de perte.
-
Utilisation de l’apprentissage adversarial pour rendre le modèle « aveugle » aux attributs sensibles. L’Adversarail machine learning, apprentissage automatique contradictoire, est une technique classique de hacker qui consiste a nourrir l’IA avec de fausses informations pour l’induire en erreur. Cette technique permet également d’apprendre à l’IA à ignorer ces erreurs.
-
-
Post-traitement
-
Calibration des scores de prédiction.
-
Ajustement des seuils de décision selon les groupes.
-
Mise en place de quotas correctifs ou de règles de rééquilibrage.
-
Le choix de la méthode dépend du contexte, mais il est souvent nécessaire de combiner plusieurs approches pour obtenir un effet tangible.
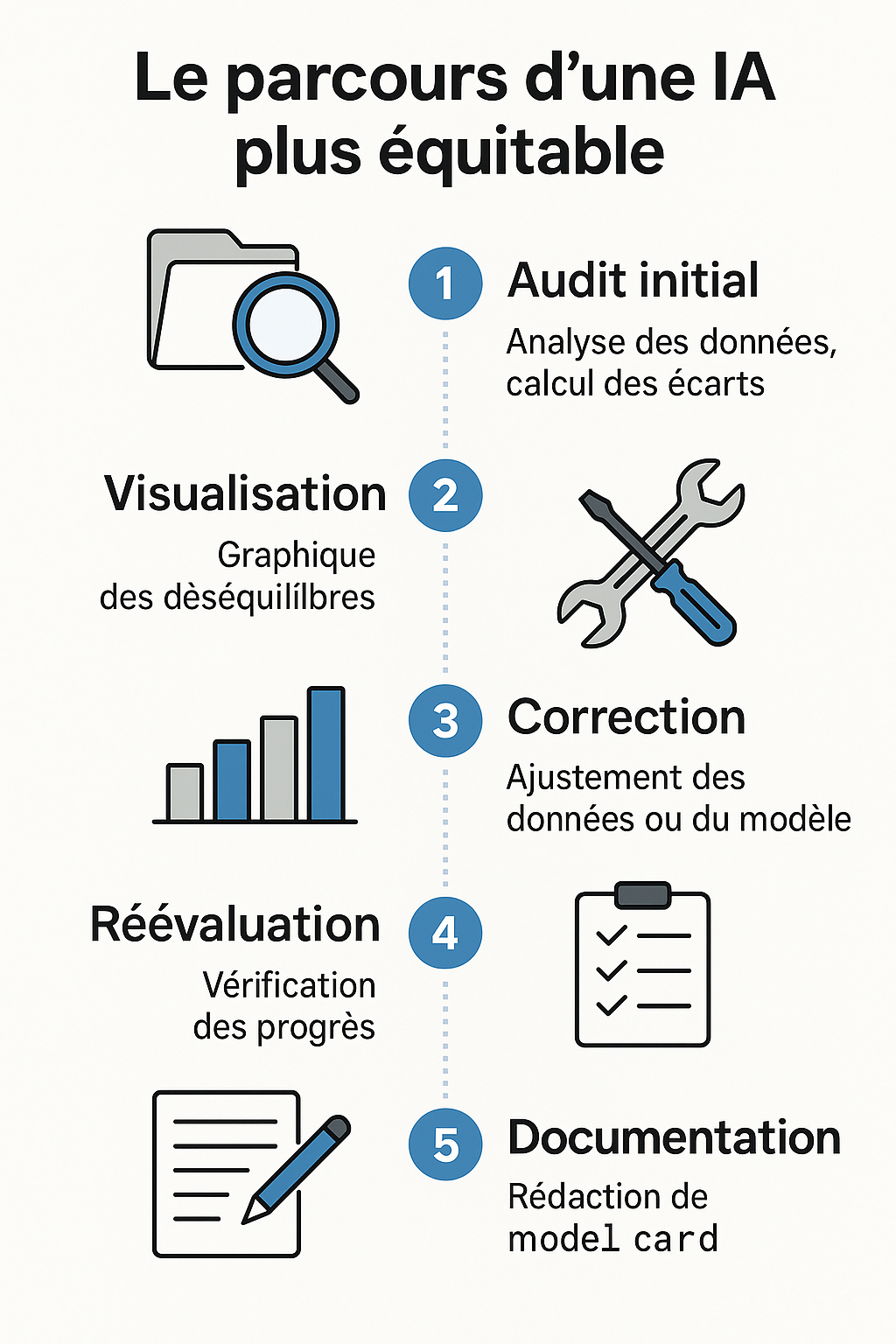
4. Parcours pratique pas-à-pas
Voici un guide simple pour appliquer ces principes :
-
Audit initial
-
Chargez vos données.
-
Identifiez les variables sensibles (genre, âge, origine, etc.).
-
Calculez l’écart de parité statistique et les autres métriques.
-
-
Visualisation
-
Tracez des diagrammes en barres pour visualiser les écarts entre groupes.
-
Repérez les déséquilibres flagrants.
-
-
Correctif
-
Appliquez des techniques de sur-échantillonnage ou générez des données synthétiques.
-
Réentraînez le modèle en incluant des contraintes d’équité.
-
-
Réévaluation
-
Recalculez les métriques.
-
Vérifiez si l’écart est tombé sous le seuil de 5 %.
-
-
Documentation
-
Rédigez une model card : un document décrivant les données utilisées, les méthodes employées, les impacts sociétaux anticipés, et les limites connues du modèle. Voir un exemple de model card.
-
Ce processus doit être itératif : corriger, mesurer, recommencer.
Conclusion
Un modèle d’intelligence artificielle n’est jamais figé. Il évolue avec les données, les usages, et les contextes. C’est pourquoi une surveillance continue et des audits réguliers sont indispensables. Détecter et atténuer les biais n’est pas un supplément d’âme pour les entreprises ni un geste de communication : c’est la condition sine qua non pour construire une IA digne de confiance et socialement acceptable.
En gardant à l’esprit que l’IA reflète le monde tel qu’il est — pas tel qu’il devrait être — nous avons la responsabilité collective de la rendre meilleure. Une IA équitable n’est pas qu’un objectif technique : c’est un choix de société.

Télécharger un exemple de model card
🧠 Points clés
Détecter et corriger les biais de l’IA
-
Un biais algorithmique = réponse injuste, exagérée ou stéréotypée
-
L’IA apprend à partir de données… qui peuvent être biaisées
-
-
Exemples courants de biais :
-
Stéréotypes culturels, de genre, géographiques
-
Généralisation abusive (« les jeunes sont toujours… », etc.)
-
Effets d’amplification ou de polarisation
-
-
Pourquoi ça arrive ?
-
Données imparfaites
-
Répétition de contenus dominants (ex. anglophones, masculins…)
-
Modèle probabiliste → il imite ce qui est le plus probable, pas ce qui est juste
-
-
Comment réagir ?
-
Analyser la réponse
-
Poser une contre-question
-
Reformuler le prompt
-
Préciser la neutralité attendue
-
-
L’IA est un outil, pas une vérité
✅ Activité – Biais ou pas biais ?
Objectif :
S’entraîner à identifier les biais dans une réponse de ChatGPT
Étapes :
-
Donnez un prompt type (ex. : « Qui sont les meilleurs leaders ? »)
-
Observez la réponse
-
Discutez :
-
Le choix des exemples est-il équilibré ?
-
Y a-t-il une omission flagrante ?
-
L’angle est-il stéréotypé ?
-
-
Reformulez le prompt pour exiger de la diversité
Durée estimée : 10 à 12 min
RESTEZ DANS LA BOUCLE







